Extractor Engine
A modular Python extraction system that isolates target fields from messy datasets and semi-structured sources — producing clean, standardized outputs ready for reporting, imports, or automation.
- ✅ Extracted dataset (CSV / JSON)
- ✅ Standardized headers + formatting
- ✅ Optional: transform rules (normalize fields)
- ✅ Summary of what was extracted
Overview
The Problem
Real-world datasets are messy: irrelevant columns, inconsistent formatting, mixed structures, and fields buried inside text. Manual filtering is slow and error-prone.
The Goal
Build a reusable extraction layer that isolates only the requested fields into a defined schema, with consistent output that can plug into other workflows.
The Solution
A Python Extractor Engine that extracts target fields, applies optional transforms, standardizes headers, and outputs clean CSV/JSON with a brief summary.
What the Extractor Does
- ✅ Isolates only the fields the client needs
- ✅ Outputs to a defined schema (consistent columns)
- ✅ Handles missing fields safely (optional defaults)
- ✅ Preserves traceability (source references when applicable)
- ✅ Normalizes whitespace/casing (as needed)
- ✅ Cleans common formatting issues
- ✅ Produces consistent headers
- ✅ Ready for CRM/import/reporting workflows
- ✅ Clean CSV and/or JSON output
- ✅ Summary: rows processed, rows extracted, skipped/failed rows
- ✅ Optional: issues log (missing/invalid fields)
Often paired with the CRK Dev Validator Engine to enforce integrity before final export.
Demo Video
This demo shows the Extractor Engine isolating fields into a clean schema, then running validation rules as the next step.
Before / After
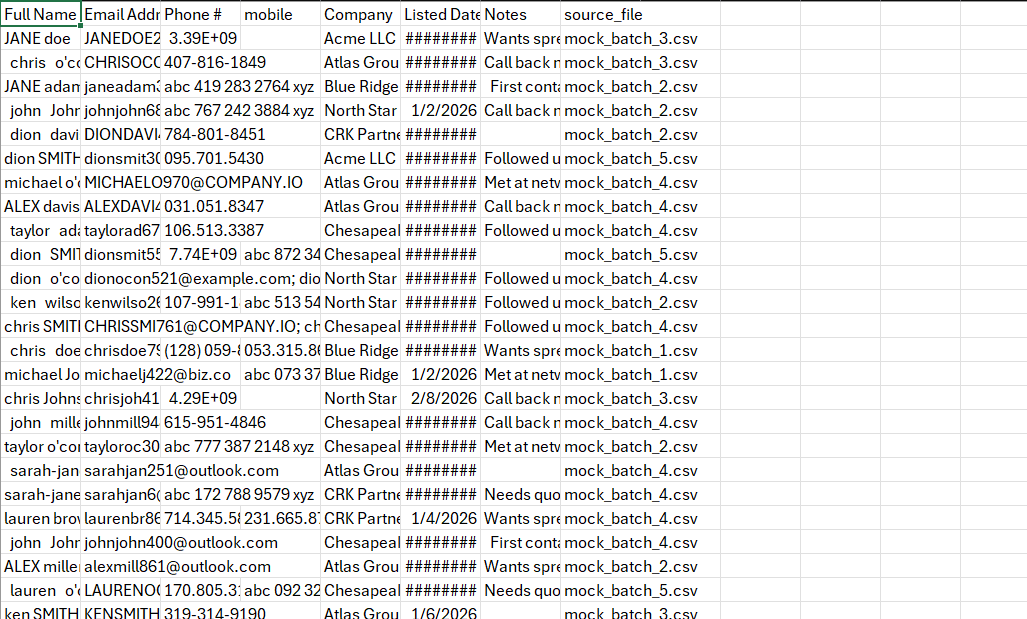
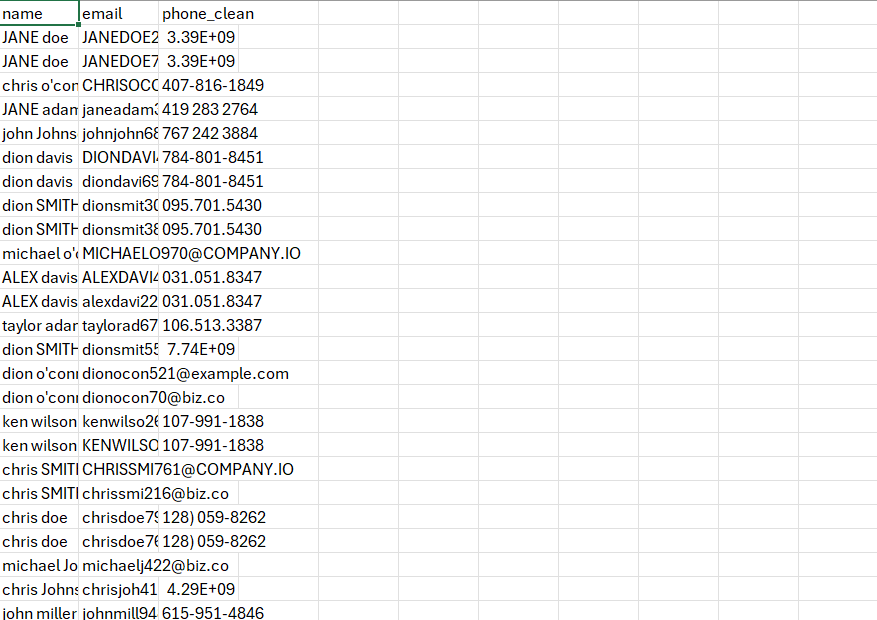
Results
Speed
Transforms raw inputs into a structured dataset far faster than manual filtering.
Consistency
Standardized schema and formatting keep output predictable across runs.
Reusability
Extraction rules can be reused as new files arrive or scope expands.
Downloads
- ✅ Example extracted CSV/JSON
- ✅ Demonstrates schema-driven output
Need data extracted from messy sources?
Send the input + the fields you need + your output format (CSV/Excel/JSON). I’ll reply with scope, timeline, and price.