Validator Engine
A modular Python validation system that enforces required fields, checks formats, flags bad rows, and produces clean outputs that won’t break downstream automation.
- ✅ Validated dataset (CSV / JSON)
- ✅ Rules: required fields + formats
- ✅ Invalid row flagging / separation
- ✅ Summary report (issues + counts)
Overview
The Problem
Automation fails when data is inconsistent: missing required values, invalid emails/URLs, wrong formats, duplicates, or broken schemas.
The Goal
Enforce data integrity before exports, imports, or automation steps — so clients can trust the output and rerun the same rules consistently.
The Solution
A Python Validator Engine that validates required fields, checks formats (regex as needed), normalizes values, flags issues, and outputs a clean dataset with a summary.
What the Validator Does
- ✅ Required field checks
- ✅ Type/format checks (regex as needed)
- ✅ URL / email validation + normalization
- ✅ Duplicate detection rules (optional)
- ✅ Valid rows output (clean dataset)
- ✅ Invalid rows flagged or separated
- ✅ Summary report (counts + top issues)
- ✅ Optional issues log for review
Typically used after extraction/scraping. See the CRK Dev Extractor Engine.
Demo Video
This demo shows the Validator Engine enforcing rules after extraction: required fields, formats, and issue handling.
Before / After
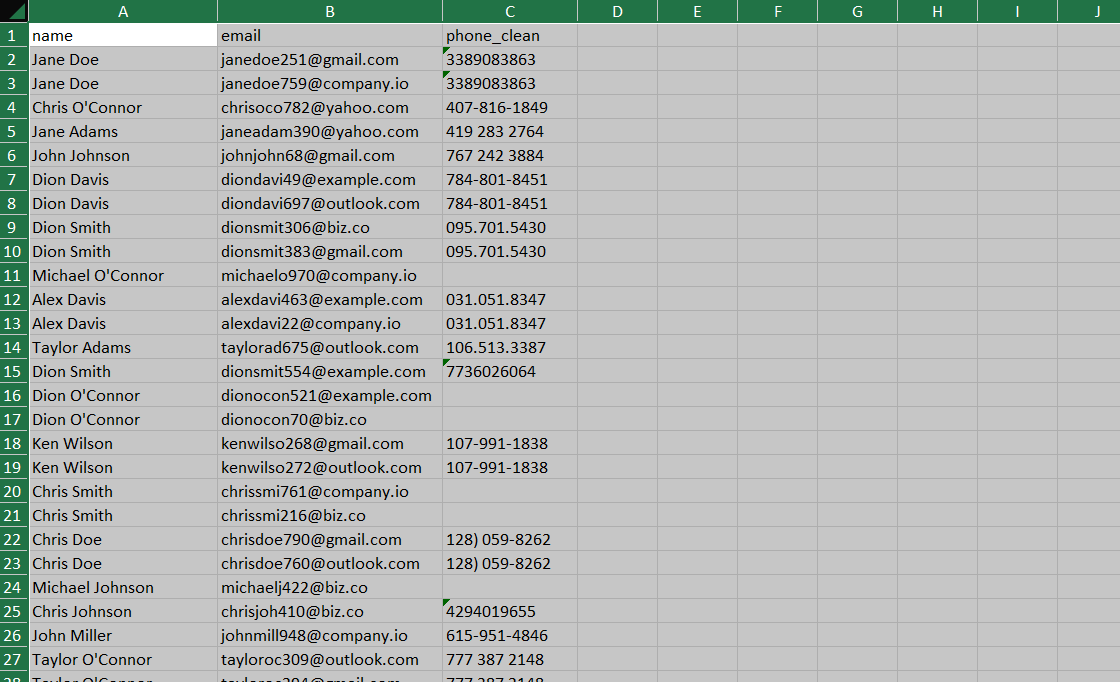
Results
Reliability
Stops broken imports and failed automations by enforcing integrity before export.
Transparency
Clear reporting shows what failed and why — so issues are actionable, not hidden.
Repeatability
Rules can be reused across runs (weekly/monthly) with consistent results.
Downloads
Need your data validated before import?
Send the file + your required fields + any formatting rules. I’ll reply with scope, timeline, and price.