Web Scraping / Data Extraction Pipeline
A Python pipeline that extracts structured data from websites and delivers clean, standardized CSV/JSON outputs — with validation, deduplication, and a clear summary of what was captured.
- ✅ Scraped dataset (CSV / JSON)
- ✅ Cleaned fields + standardized headers
- ✅ Validation + dedupe rules (as needed)
- ✅ Summary of what was extracted
Overview
The Problem
Many sites present useful information as human-readable pages (directories, listings, catalogs) — but clients need that information in a structured format for Excel, CRMs, reporting, or automation.
The Goal
Create a repeatable, scope-first scraping workflow that extracts the requested fields accurately, keeps the dataset consistent, and delivers clean outputs without manual copy/paste.
The Solution
A Python-based Web Scraper Engine that collects target pages, extracts fields to a defined schema, validates key columns, deduplicates, and exports clean CSV/JSON with a summary report.
What the Web Scraper Does
- ✅ Collect target URLs (seed pages + pagination)
- ✅ Extract requested fields into rows (schema-driven)
- ✅ Capture source URL per row (traceability)
- ✅ Handle common edge cases (missing fields)
- ✅ Normalize casing/whitespace (as needed)
- ✅ Standardize headers and formats
- ✅ Validate required fields (optional rules)
- ✅ Dedupe by exact match or key columns
- ✅ Clean CSV and/or JSON output
- ✅ Brief summary: pages scanned, rows extracted, skipped/failed rows
- ✅ Optional: “issues” log (missing required fields / parse errors)
Demo Video
Before / After
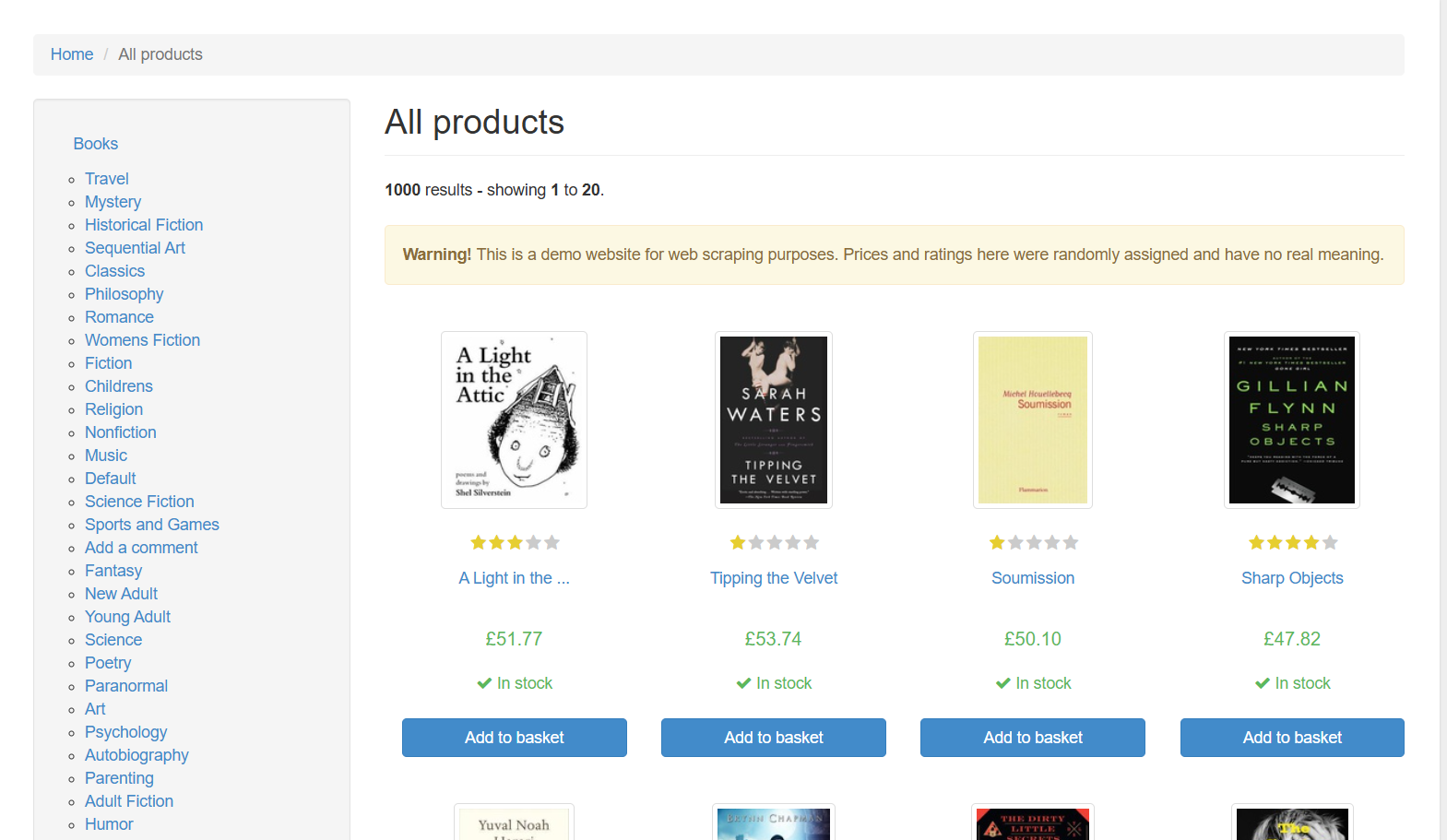
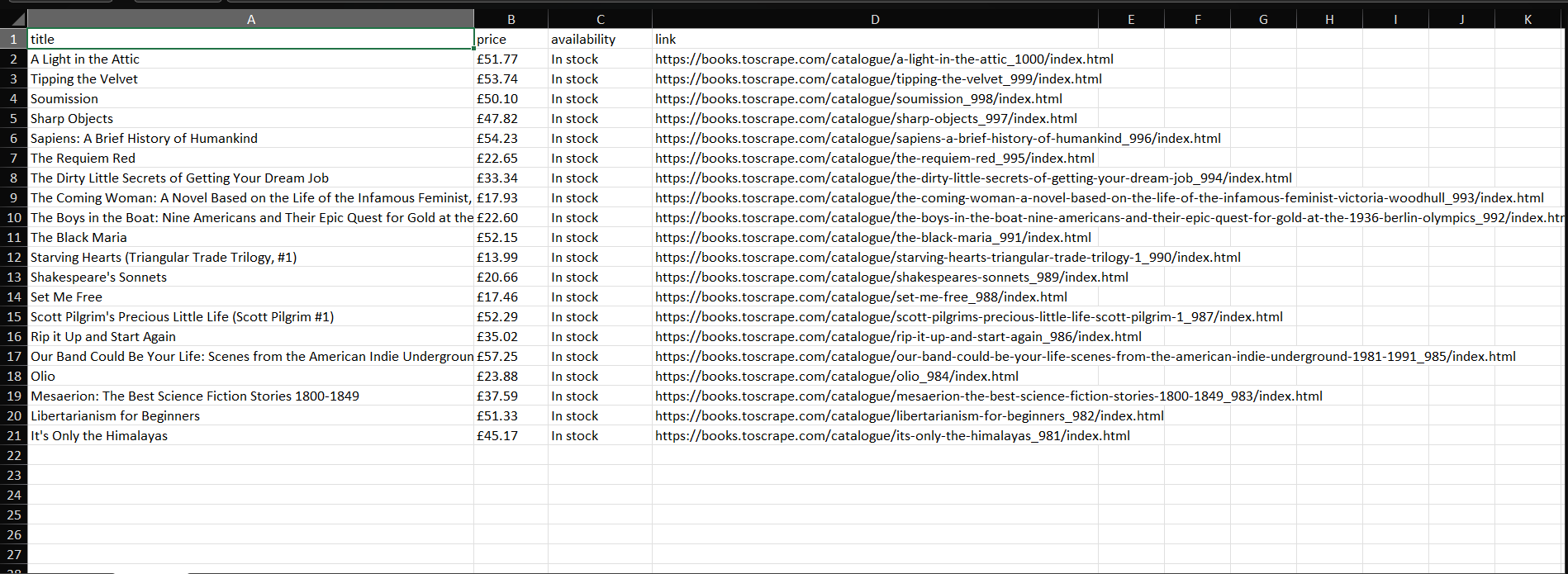
Results
Speed
Extracts large sets of structured rows far faster than manual copy/paste or browsing.
Consistency
Standardized columns and formatting make data ready for Excel, imports, reporting, or automation.
Reusability
A pipeline approach allows repeat runs as new pages appear or as the client updates scope.
What clients typically care about
- ✅ “Are the fields extracted consistently across all pages?”
- ✅ “Can I trust the output (source URL + validation)?”
- ✅ “Are duplicates handled correctly for my use case?”
- ✅ “Can we rerun this weekly/monthly with the same rules?”
Downloads
- ✅ Example: URL list (or seed page) for scraping
- ✅ Demonstrates target fields + schema expectations
- ✅ Structured rows with consistent columns
- ✅ Cleaned + deduped (as needed)
Need data extracted from a website?
Send the site + the fields you want + your output format (CSV/Excel/JSON). I’ll reply with scope, timeline, and price.